BankBot
An intent-based classifier chatbot that helps bank customers with simple information provision and tasks.
The GitHub repository for this project is located here.
Group Members
Topic Brainstorming & Leadership:
William Daniels, Andrew Rodrigue, Caleb Walls, Ben Alterman, Emilia Garcia-Saravia
Programming, Implementation, and Experimentation:
William Daniels
Data Collection and Production:
Ben Alterman, Emilia Garcia-Saravia, Kha Le, Hieu Mai, Jorie Noll, Marcellina Kazigati, Ana Nuno, Adwaita Ramachandran, Andrew Rodrigue, Caleb Walls
Project Report:
Emilia Garcia-Saravia, Ana Nuno, Marcellina Kazigati, William Daniels
Presentation:
Ben Alterman, Emilia Garcia-Saravia, Kha Le, Hieu Mai, Jorie Noll, Marcellina Kazigati, William Daniels, Ana Nuno, Adwaita Ramachandran, Andrew Rodrigue, Caleb Walls
Abstract
The purpose of this project was to develop a computer program that implements an intelligent agent that will resolve a bank’s online customers’ common issues. The baking system’s customers could have issues that range from activating a new card to editing user information. To solve this problem, we opted to create a chatbot that is intent based. This is achieved through the development of a deep neural network model to fit training data to be later used to predict the correct intent when a customer inputs their own query. To interface with the bot a GUI was implemented. The result was a chat bot, BankBot4444, with a series of unique responses based on intent. The model will go through two experiments to increase its performance and accuracy. One of the experiments will be testing the model using various hyperparameters. Another experiment that will be formed is text normalization and elimination of noise in the data through the elimination of stopwords.
Motivation
To develop a computer program that implements an intelligent agent that will resolve the problem below. We decided to implement a chatbot using a deep neural network to handle common questions to allow human customer support agents to focus on more difficult tasks.
Problem
A bank’s online customers are in need of assistance with questions and problems. The banking company would like to have a chatbot that would provide unique responses each time a new user interacts with it.
Idea and Concepts
- Bag of words
- Text Normalization
- Neural Networks
- Text Formatting and Tokenization
- Intent-based structure
Software System Design and Implementation
Overview
Our goal in this project was to get a deep neural network model to fit the training data, which is example queries associated with the intent of the query, and use this model to predict the correct intent when a customer inputs their own query.
We transform our training data into JSON format where the tag specifies an intent, the pattern represents the training query, and the response represents a few output selections of which the program could respond to the user with. (Tags are synonymous with intents and may be used interchangeably with each other for the purposes of this report.)
To interface with our bot, we implemented a GUI in the form of a PyQt5 MainWindow class.
Data Gathering
For our data we used this intent classification dataset centered around banking queries:
Source: Efficient Intent Detection with Dual Sentence Encoders
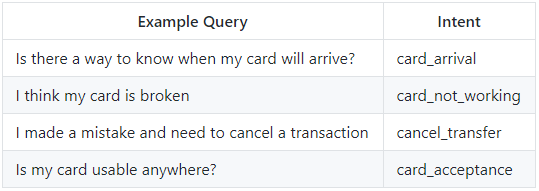
We then transformed this dataset into JSON format and manually inputted the respective responses for each intent classification (average of 5 responses for each intent = 5 * 91 = 455 responses)

Preprocessing Data
First, we take data from the JSON file and create a series of lists to store the various tags, patterns, and responses.
We then use a Keras Tokenizer to fit every word present in the pattern to a word index (a dictionary of words ranked by frequency). In this way, every phrase can be transformed into an array of numbers. Tags are tokenized as well.
The ‘makeInput’ function takes the tokenizer object and a list of all the patterns to create a list of lists where each list is a bag of words representation of each pattern as it relates to the word index (if a word has a key of x in the word index, whether it is found in the pattern is represented by either a 0 (not present) or a 1 (present) in the x-1 index of the list).
The ‘makeOutput’ function has the exact same purpose that the ‘makeInput’ function has but for tags. So the intents that the patterns will be mapped to have their own bag of words representation, although in this case, one intent doesn’t appear more than another, so the order they are indexed into this bag is arbitrary.
We transform both the inputList and outputList returned by both make functions and transform them into NumPy arrays to be compatible with our model.
Creating and Training the Model
Using a tflearn DNN (deep neural network), we construct a model with 5 layers:
- Input layer with a shape equivalent to the length of our bag of words
- Dense layer where the number of neurons is the variable ‘n’
- Dense layer where the number of neurons is the variable ‘n’
- Dense layer where the number of neurons is the number of possible tags, with a softmax activation
- Regression layer
We fit our model with the input and output array and set it to train for 10 epochs (10 is an arbitrary number used for epochs, we will focus on choosing a better value later).
Predict from Trained Model
Our ‘interact’ function predicts an intent and selects a random response based on the intent. This function is a part of the PyQt5 GUI we used as an interface for the bot, more on this later.
More specifically, the ‘interact’ function takes user input, transforms that input through the use of ‘makeInput’ into a NumPy array, uses the model to predict the most likely label from that NumPy array, and randomly selects a response from a list of responses that relate to that intent.
Creating a User Interface
A separate GUI file, named ‘gui.py’, is used as the PyQt5 class that is subclassed inside of the file that runs our chatbot.
When the GUI file is subclassed, it allows us to add PyQt5 user interface functionality, such as user input that can be converted and prediction response output from our bot that can be displayed. (As there is no send button implemented, user input is received by the user with the return button. This is not an oversight, but a design choice.)
For styling, we use a CSS stylesheet called qdarkstyle. Which results in the dark mode styling you see in the interface.



Experiments Performed and Results
Choosing Hyperparameters
For testing purposes, we set arbitrary hyperparameters for the neural network to focus on the actual implementation. These hyperparameters consisted of:
- Epochs = 10
- Number of neurons per dense layer (n) = the average of the input and output sizes = (input size + output size)/2
This resulted in performance sufficient enough to test our bot, but the performance was subpar nonetheless with an accuracy of around 86 to 87 percent reliably.
Choosing Hyperparameters (Results)
By running tests on various hyperparameters, we concluded that lowering the number of neurons per layer and increasing the number of epochs granted the highest model accuracy.
We also needed to avoid overfitting the model, so we needed to find the best spot where the accuracy to time trained ratio was maximal.
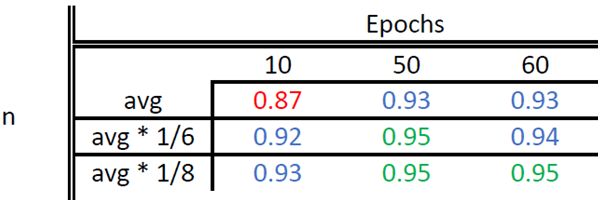
avg = (input size + output size)/2
avg * 1/6 = (input size + output size)/12
avg * 1/8 = (input size + output size)/16
Accuracy peaks (with least chance of overfitting) with a combination of:
- Epochs = 50
- Number of neurons per dense layer (n) = avg * 1/6 (which is equivalent to 343 neurons per dense layer at final testing)
Morphological Word Analysis: Text/Word Normalization
We can increase the accuracy of our model even further by considering what word data we feed to our model and morphing it to our advantage.
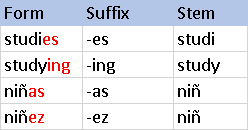
According to Wikipedia, morphology “is the study of words, how they are formed, and their relationship to other words in the same language. It analyzes the structure of words and parts of words, such as stems, root words, prefixes, and suffixes.”
Techniques like stemming, the reduction of a word to a root form, and lemmatization, the reduction of a word to a root word, we theorized, could help us eliminate noise in our word data and give our model even greater accuracy.

In addition to text normalization, we can eliminate other noise from our data in the form of removing stopwords.
Stopwords are the most common words used in everyday language and usually provide no useful information to our model, decreasing the accuracy.

Morphological Word Analysis: Text/Word Normalization (Results)
We devised an experiment that counted the accuracy of the model (given the previously chosen parameters) when stemming, lemmatization, and neither were used with and without removing stopwords, resulting in 6 permutations of text augmentation.
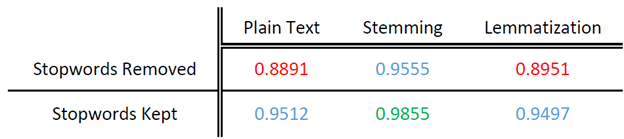
As shown in the results, removing stopwords was very detrimental to the accuracy of our bot. This outcome should be somewhat anticipated for a chatbot, but since there were so many keywords for our chatbot model to pick up on we considered stopwords to be extra noise, which evidently is not the case.
Lemmatization seemed to not contribute much to the accuracy of the model, even decreasing the accuracy later. It’s hard to deduce the reason for this, but one very plausible assumption is that in this dataset there are a few words that, when reduced to their root word through lemmatization, turn out to be the same word, even though they have slightly different meanings.
Stemming, however, had a massive increase in accuracy, increasing it by a net of 3 to 7 percent depending on whether stopwords were kept. This is probably due to having all the advantages that text normalization gives (reducing words to their meanings without noise) without the disadvantages that lemmatization brought to our specific problem.
The most powerful combination for our model was stemming all words, including stopwords. The result was a model accuracy of 98.55%, an improvement of around 3.5% over the last experiment’s resulting model accuracy.
Software Tools and Packages
NLTK: A platform for building Python programs to work with human language data.
Tensorflow: A free and open-source software library for machine learning. It can be used across a range of tasks but has a particular focus on training and inference of deep neural networks.
Tflearn: Designed to provide a higher-level API to TensorFlow to facilitate and speed-up experimentations.
Keras: An open-source library that provides a Python interface for artificial neural networks. It acts as an interface for Tensorflow.
PyQt5: Python binding of the cross-platform GUI toolkit Qt implemented as a Python plug-in.
Numpy: Python library for manipulating arrays and numerical computations.
Pandas: Python library for the creation and manipulation of data frames as well as graphing.
Qdarkstyle: A dark stylesheet for Python and Qt applications
Summary
The goal of this project was to create an intelligent agent that would help solve a bank’s customers’ problems. The solution was to create an intent-based chatbot. We achieved this by using a deep neural network model to predict the correct intent when a customer inputs their own query. To increase the accuracy of our model two experiments were performed. By running tests on various hyperparameters, we concluded that lowering the number of neurons per layer and increasing the number of epochs granted the highest model accuracy. Additionally, text normalization and removal of stopwords were tested. We devised an experiment that counted the accuracy of the model (given the previously chosen parameters) when stemming, lemmatization, and neither were used with and without removing stopwords. The best combination of methods was stemming all words, including stopwords that resulted in an increase of accuracy of our model.
References
Efficient Intent Detection with Dual Sentence Encoders by Inigo Casanueva, Tadas Temcinas, Daniela Gerz, Matthew Henderson, and Ivan Vulic.